
“Data is the new oil,” has become a common analogy for explaining the increasing value data is having on our society and economy as a whole. In 2017, an article was published in The Economist titled “The world’s most valuable resource is no longer oil, but data,” which is likely the source of this concept. While this comparison is an enlightening one in many ways, one key difference between oil and data is that oil is a finite resource while more data can be generated infinitely, given time.
Machine learning and artificial intelligence are two terms you may be hearing about more and more these days, with the intent to leverage the mass amounts of data being generated. Along with the increased awareness and adoption of this technology, organizations are seeing true returns on investment. A 2022 survey shows that 92% of large companies are seeing a return on their data and machine learning investments, up from just 48% in 2017.
So, if data is our most valuable resource and is something we are able to continuously generate, it is quickly becoming time-sensitive for organizations to review their current data collection and storage processes. More explicitly,
if you aren’t currently collecting and managing your data systematically, you’re likely falling behind.
Terms like ‘machine learning,’ ‘artificial intelligence,’ and ‘algorithm’ often portray a magical process where one simply needs to shove data into a model or computer program, and amazing insights instantly become available. The perhaps unfortunate truth is that the ability of this technology to produce meaningful and useful results is much more dependent on the data itself than on the specific model or algorithm. At the risk of reducing some of the allure of this innovative field that perhaps makes it attractive, the majority of machine-learning methodology (like traditional statistical methodology) is based on understood, well-established, and freely available algorithms and techniques.
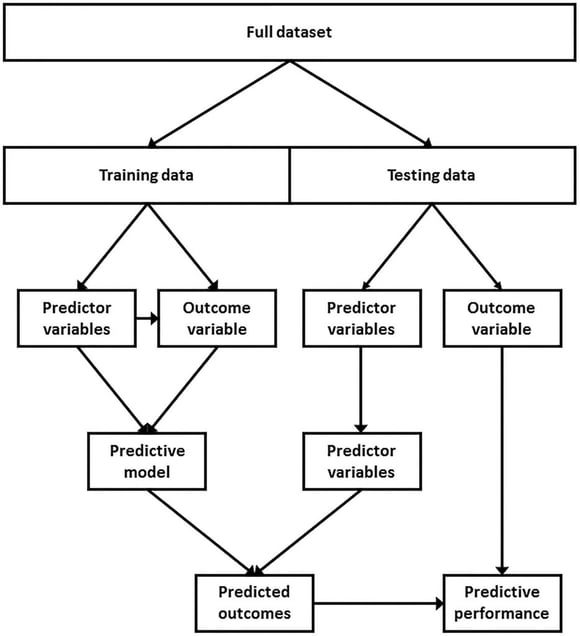
The fact that this concept is no different from traditional statistical methodology seems to be missed both in the public domain and often even in the academic literature. The term “proprietary algorithm” is often used to cover up this misunderstanding as a "black-box" private industry development, which is simply not the case. Just like using the Analysis ToolPak in Microsoft Excel (SPSS, MATLAB), machine-learning engineers utilize existing tools and approaches and have a variety of different methods at their disposal.
These advanced tools are inherently different from those that utilize a more traditional statistical approach but are not themselves proprietary.
These models are complex. For example, neural networks were designed based on our understanding of how the human brain works, but not magic. The famous quote attributed to British statistician George Box, “All models are wrong, but some are useful,” can also apply here. Models can tell us interesting and sometimes useful information, but again, it’s the data that matters most. Start collecting!
Perhaps less obvious unless stated: the massive quantities of data that are continuously being generated today primarily come from the real world, not the lab. The cost and availability of technology to instrument and collect data on pretty much anything and everything has greatly improved. So, the majority of human data captured from technology like wearables, force plates, and motion capture devices are no longer coming from the painstaking standardized and controlled experiment environment of clinical researchers but from everyday practitioners utilizing these devices.

In general, this is a good thing: more data is being generated. But without some amount of standardization (as every good researcher knows), we run the risk of collecting low-quality (unreliable) data. Since we know the data itself is much more important than the models, this is the real challenge and prerequisite step for the real-world operational utility of data.
In their book Real World AI, authors Alyssa Simpson Rochwerger and Wilson Pang highlight this as a key difference between industry and academic data science cultures:
“This is a reversal of the typical paradigm represented by academia, where data science PhDs spend most of their focus and effort on creating new models. But the data used to train models in academia are only meant to prove the functionality of the model, not solve real problems. Out in the real world, high-quality and accurate data that can be used to train a working model is incredibly tricky to collect.”
Organizations attempting to pursue a data-driven approach need to proceed with caution if the data collection process isn’t optimized for this. In this case, we have two suboptimal results: researchers or data scientists need to participate in all data collection, OR the quality of the data collected by the layperson may be questionable.
It is important to note that even with what we’d call high-quality or reliable data, there is no guarantee that modeling will be useful. For example, we likely wouldn’t be able to develop a useful weather forecast for Adelaide, Australia, using historical data from Tulsa, Oklahoma. There is no “free lunch” with predictive modeling.
Here at Sparta Science, we have been collecting, storing, and analyzing relevant human data for over a decade with amazing learnings. However, the applicability of existing insights can be more limited in new populations or unique environments as we continue to grow into new areas. Historical data modeling still provides significant out-of-the-box utility, but for organizations interested in optimizing and customizing insights, the time needed to generate relevant, high-quality data is not something that can be bought.
Machine learning does support mining historical human data for insights and learning, which can provide organizations with a head start for operationalizing this data.
But, to leverage the true value of data, a long-term perspective is required. Not only is this approach best to manage expectations, but it also enables organizations and individuals to objectively validate the data and model themselves. It can be easy to point to the results of an existing research paper or a related organization’s success as validation for your organization’s utilization of data. But without truly validating, do you know? Additionally, the appropriate interpretation of results and downstream utility of data for decision-making may be unique for each organization or customer, and thus, the data and technology need to be optimized appropriately.
This cannot and should not be seen as a threat to the human practitioners in the field. With almost every new major innovation, concern arises that automation and computers are going to make humans obsolete; the reality couldn’t be further from the truth. The ability to automate manufacturing processes has greatly improved efficiency and safety for workers without removing the need for humans. Technology and data innovations in human movement health are no different. Advances here will better inform and enable humans to make better decisions.
While some challenges may be better addressed through data, many of the most important ones require human intellect and interaction, with the combination of data and expertise being the most effective. Data and technology can’t replace, but can help to make each individual exponentially more effective: it’s a multiplier.