
January 22, 2023

We are currently in the midst of the fourth industrial revolution: AI, ML, and Big Data. Like the invention of the steam engine, electricity, and computers before, AI and Big Data have the potential to vastly change how humans learn, interact, and engage with the world around us. The utilization of AI/ML is growing in various fields at varying rates. The availability of big datasets in these industries primarily impacts this. Healthcare has been comparatively slow in adopting some of these more innovative approaches. The COVID-19 pandemic has provided a catalyst for change yet highlighted many current limitations and challenges hindering our ability to leverage big data in the healthcare industry.
What is Big Data?
Before discussing specific examples, we should take a quick step back to ensure we understand what Big Data means. Data that is described as Big Data is often assumed to meet four specific criteria, commonly referred to as the Four V's:
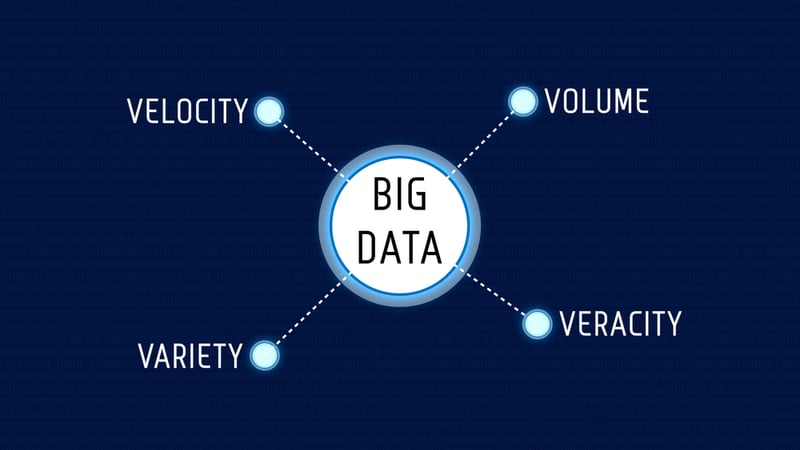
-
Volume - Perhaps most straightforward to understand, big data refers to large quantities of data. This is one of many prerequisites, however.
-
Variety - Multiple data types are also necessary for a big data approach. AI is best leveraged for solving complex problems. Therefore a variety of contextual data is required to account for these complexities and their potential interactions.
-
Velocity - A characteristic of Big Data that should be discussed more is how fast the data is generated. This is a critical component as consistent and continuous data generation is needed for iterative model development, continuous learning, and the most up-to-date insights.
-
Veracity - Last and certainly not least, veracity refers to the reliability or integrity of the data. High-quality, accurate data from trusted sources are foundational to enable accurate insights.
Why do we need Big Data?
While many individuals are excited about the potential benefits of this revolution, they are justifiably still a few skeptics that may question the utility of big data in specific applications. Many of our healthcare decisions are driven by objective testing, diagnostics, and clinical trials. Yet, the clinical expertise and the personal human interaction between patient and provider continue to be critical components that drive successful healthcare outcomes. These skeptics need to understand that this revolution is not intended to replace this human interaction but to augment and improve it.

To better understand the intent and, therefore, the promise of AI/ML, we can look to what is the foundation for much of the innovation here: the human brain. Neuroscientists often explain the brain as a prediction machine; it is continuously flooded with countless inputs (raw data) from our sensory organs and tasked to generate meaningful information, predictions, and drive decisions. A comedic yet intuitive example of these predictions and decisions, framed as bets, may help to understand this analogy. This constant stream of inputs no doubt checks the boxes of the Four V's and can be considered Big Data!
Artificial Intelligence (AI) is largely intended to mimic the amazing intelligence capabilities of humans. Neural networks, for example, are designed to function based on our best current understanding of how the human brain works. Both of these capabilities, AI and HI (Human Intelligence), have their limitations. For example, the human brain's capacity is limited, and its memory is imperfect. At the same time, AI generally requires human input, contextual expertise, and significant front-end technical development to deploy and implement. The optimal approach is a combination of the two. Given this understanding, the thought of an AI model acting as an additional "expert opinion" is perhaps a bit more attractive. However, the better comparison may be that the model represents hundreds or even thousands of additional "expert opinions," given the limitless capacity of computer processing. Experts agree… the more experts, the better!
Big Data and AI in Healthcare
We have previously highlighted many examples of how the AI revolution has changed our lives in other industries. Still, there has been significant progress in applying these innovations in healthcare. As we might expect, most of the effort here has been focused on where big datasets have historically been generated and currently exist.
Imaging Diagnostics - Digital imaging has generated a treasure trove of big data that can be utilized to train AI/ML models. One example of this comes from a study led by Tulane University that generated a model that could identify colon cancer as accurately as a trained pathologist.
Prescription Adherence and Addiction - Express Scripts is a company that has utilized a big data approach to predict scenarios such as who is not adhering to treatment or who is likely to become addicted to a particular medication. As an outcome, they have reportedly cut the non-adherence rate of some patients in half!
Real-Time Alert Response - We need to look no further than the latest phone and watch from Apple, consumer-accessible technology that utilizes AI to automatically detect when a user is in an accident, alerting loved ones and emergency services in real-time.
Operations and Billing - Another big data source comes from EHR systems and insurance billing documentation that is being leveraged to automatically identify and correct billing errors to improve efficiency. Additionally, Natural Language Processing (NLP) technology can annotate physicians' verbal notes directly to billing codes.
Challenges for Movement-Focused Healthcare Providers
While the Healthcare industry has generally lagged behind other sectors in adopting big data approaches, Movement Health as a specialty is even further behind other healthcare specialties. As mentioned above, one of the main reasons is that large, clinically relevant datasets related to Movement Health are scarce. Why is that?

For large volumes of data to be generated, measurement and instrumentation must be widely available and accessible. Historically, in Movement Health, measurement is performed irregularly due to the time burden of conducting assessments and requirements related to insurance and billing. Undoubtedly, a large variety of relevant data types can be generated. Various objective and subjective evaluations, patient-reported outcome measures (PROMs), exercise and other prescribed treatments, and other outcome measures like re-injury and re-admittance rates can all be leveraged for data analysis. The majority of this data, unfortunately, has not been systematically collected, stored, or aggregated. Historically, the primary strategy for collecting this data has been in the context of billing, where a "bare minimum" justification has been the standard.
With so few existing big datasets relevant to Movement Health, it is clear that there has yet to be a high velocity of data being generated. Until recently, most of the objects we commonly use, cars and watches, for example, did not produce or handle data and lacked internet connectivity. The large-scale instrumentation of these devices has led to innovations such as self-driving cars and automated accident detection, as mentioned above. New technologies in the Movement Health space are now making large-scale instrumentation possible but still require organizations to implement at scale to make this a reality. The growth and now ubiquitous use of EHR systems has generated large datasets for innovation. However, the aggregation of these data sets between organizations and providers is limited. To aggregate data, we must be able to trust its quality or veracity. A lack of standardization across and even within EHR technologies currently limits the interoperability of this data at the most significant scale. For Movement Health providers to leverage and learn from their data to improve operational and clinical efficiency, systematic, integrated data collection and aggregation must be a priority.
Take Home
Data collection now is the lifeblood of future understanding. The industries and organizations that have benefited the most from the AI revolution are those that got a headstart with existing big datasets. For the future of Movement Health providers, it is up to those with the foresight and discipline to invest in systematic instrumentation and (BIG) data collection.
