
March 18, 2021
As the human performance industry advances, technologies, new and old, continue to try to innovate and differentiate themselves for your dollars. Almost every technology company these days, including Sparta Science, is collecting data and will lean on their “data-driven insights” as a way to pique your interest before going on to tell you all about the value you or your organization will receive from their respective solutions. But, before even discussing the “insights,” let’s dive into the first question tech companies should ask themselves AND you should ask of them…
Are your measures reliable?
pre·ci·sion /prəˈsiZHən/ noun: the quality, condition, or fact of being exact and accurate.
The two most important aspects of precision are reliability and validity. Reliability is measuring something consistently (reproducibility), and when it comes to reliably assessing human movement, it is most important for tracking changes within individuals. Validity is some measure of association with another measure, answering the question, “How well does the measure, measure what it’s supposed to?“ Validity is important for distinguishing between individuals. It is important to understand that reliability is a precursor to validity. That is, if the results of a test cannot be assigned consistently (reliable), it is impossible to conclude that the scores accurately measure the domain of interest.
Reliability is the ability to get the same results with the same measurements consistently. For example, if I step on and off a scale multiple times, a reliable scale will keep giving me the same number. Reliability is often assessed utilizing some sort of test-retest correlation. In the example just referenced, I first perform a test: my initial weigh-in on the scale, say 220.8. Then I perform the retest (often on a different day), getting another data point for my new weight, for example, 222.1. If we do this a large enough number of times with a large enough population of people, we can use this data to analyze if the scale itself is reliable. Obviously, a reliable scale should give us a similar value each time we step on it.
There are a few different statistical tests that can give us a specific measure of how reliable this scale is. A couple of examples of measures these tests produce are Cronbach’s Alpha and Intraclass Correlation Coefficient, with both falling somewhere between 0 and 1. The closer to 1, the better, with anything below 0.5 usually deemed as being unreliable.
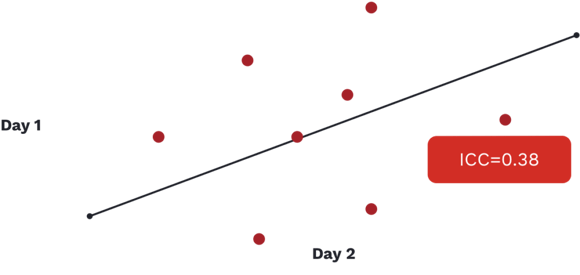
In the above image, we see an ICC value reported for a commonly used movement screen that is well below the accepted range of what we would deem a reliable test (1). It is an important graphic to show as the screen being referenced is extremely popular and continues to be utilized in a variety of organizations, from hospitals focused on health and wellness to elite sporting and military organizations looking for that extra 1%, despite its lack of reliability.
To reiterate the importance of reliability, remember, that if a test’s results cannot be assigned consistently (reliable), it is impossible to conclude that the scores accurately measure the domain of interest.
Basic Reliability:
- Chances that a measure will produce a similar result when repeated under similar conditions (repeatability)
- “Error” in repeatability can be due to the individual or the technology
- Represented by some form of test-retest correlation (1.0 = 100% chance of a similar measure and 0.0 = a 0% chance of a similar measure) – Example: intraclass correlation coefficient (ICC = 0.85)
Reliability is often overlooked because it isn’t fun or sexy, but is it of the utmost importance. It is also important to understand that we need to evaluate each unique test’s reliability, metric, measure, or variable we are collecting and hoping to use. To use an example familiar to us, literature on the vertical jump is often cited as being a reliable test and force plates are often cited as being reliable measuring devices…but it really isn’t that simple. Reliability is specific: it depends on what exactly we are measuring and how exactly we measure it.
References
-
Gribble PA, Brigle J, Pietrosimone BG, Pfile KR, Webster KA. Intrarater reliability of the Functional Movement Screen. J Strength Condit Res. 2012;26(2):408‐415.