

This week we will continue to dive a bit deeper into some of the methodologies we utilize here at Sparta Science that differ from most traditional data science techniques. As we’ve discussed in recent posts, the utilization of machine learning (ML) is growing exponentially in many industries enabling a “big data” approach to leverage the massive amounts of data being generated.
How much data? Today an estimated 2.5 exabytes of structured, semi-structured, and unstructured data are generated daily. That’s enough data to fill up 20 million iPhones daily!
Before the digital age, the majority of data that existed was small, organized, and structured. Think of this data as the data you could collect by hand and write into a notebook in tabulated columns and rows. Since this “small data” is all that existed until the advent of computers, the development of long-standing traditional statistical methods were optimized to extract information from these small datasets.

Today’s datasets are exponentially larger and more complex than the datasets from which the foundation of “small data” analysis was developed. This ‘heap’ of exponentially growing data is an accumulating asset, from which we can extract meaningful insights and information with more advanced techniques. Traditional statistical techniques still provide great value and are foundational to the analysis of small, structured data sets, but more complex methods such as unsupervised learning techniques are growing in popularity due to the poor applicability of traditional methods on large complex data sets.
What is unsupervised learning?
Unsupervised learning is a type of “big data” methodology used to analyze datasets to explore and identify hidden patterns or groupings within the data. The term “unsupervised” comes from the fact that the groups that are generated are not related to any specific labeled outcome or result. For example, a clustering technique can be used to place users with similar credit card purchasing behavior into distinct groups, without having the corresponding labels of which purchases are genuine and which are fraud.
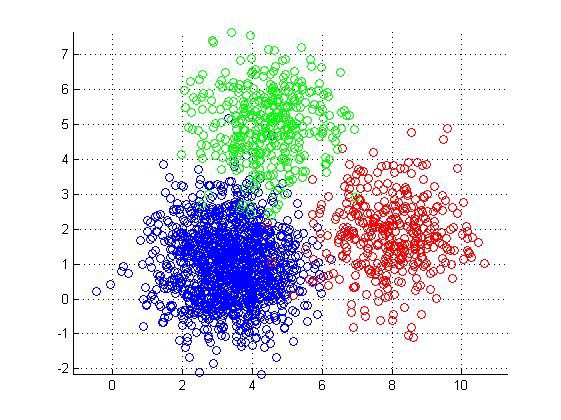
To continue on with our credit card example, the results of these iterative clustering analyses can provide meaningful insights into the ‘typical’ behavior of different purchaser ‘profiles’ and be used to guide further analysis. Even without the labeled data, it is possible to flag fraudulent purchases by monitoring when a user’s behavior becomes ‘atypical,’ or in other words, when their cluster changes.
Clustering human movement data
Most unsupervised learning methods and techniques utilize well-established algorithms and tools to explore and discover patterns. However in the literature, the application of these techniques on different types of human physiological data, and more specifically human movement data (e.g. kinetic, kinematic), is relatively scarce. This reflects a large untapped opportunity to leverage the growing breadth and depth of movement health data to provide insight to practitioners and organizations.
Similar to how credit card companies leverage machine learning technology to cluster the typical behavior of their customers, data scientists in the literature have begun to use unsupervised learning techniques with movement data to identify hidden patterns and groupings in movement strategies, capabilities, demands, and physiological characteristics. For example, one research group utilized wearable GPS and accelerometer data collected during American Football games to identify unique groupings that characterize the typical demands of a football game (1). Coaches and practitioners can ultimately use this information to split players into similar training groups to better optimize physical training programming based on each athlete’s demands.
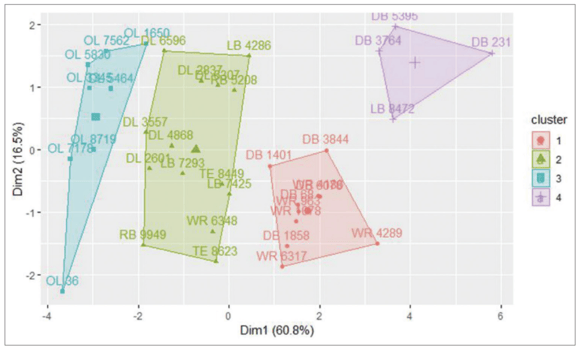
Through a combination of techniques (clustering and dimensionality reduction), they ultimately discovered that while the three traditional groupings by position often used in American football (Big, Big Skill, and Skill) do hold some merit, the style of play and workload of some players often categorized them into a group different from their position. For example, a Linebacker that would generally be considered a part of the “Big Skill” grouping, may in fact be more similar to a Defensive Back or “Skill” player based on their wearable data. Additionally, the research suggests that four groupings uncovered through unsupervised learning techniques may be more optimal than the traditional three groups for training purposes. Large amounts of human physiological data analyzed in this way can not only help to validate intuition, but to tweak and optimize best practices to better address individual physiological needs.
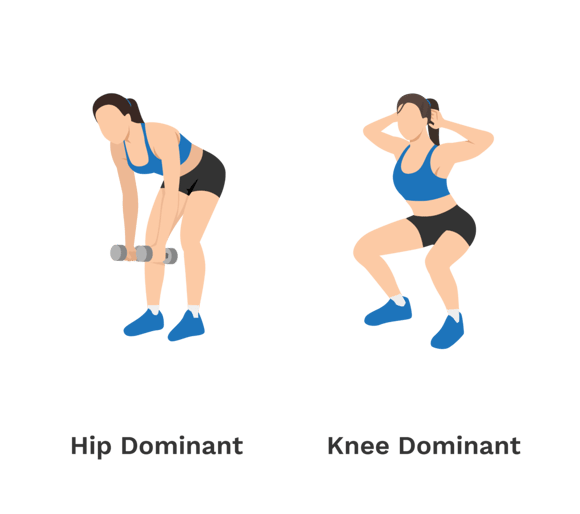
Another study utilized a combination of high bandwidth kinetic (force plate) and low bandwidth kinematic (motion capture) data collected on professional basketball players to develop unique clusters based on their dynamic movement strategy (2). The ability to jump high is no doubt a common thread among basketball players, however the movement strategies utilized can vary greatly. For example, different individuals may be categorized as being either knee-dominant or hip-dominant while they jump, yet this strategy may not significantly impact jump height! Clustering analyses allow us to take an objective approach to identify what unique groupings of movement strategies exist.
Ultimately the goal of all of this analysis and data science is to learn something meaningful that we can implement or utilize to better improve our outcomes and processes. Learning about how we can categorize different movement strategies of NBA players is no doubt interesting, but how does that information help us?
Learning from data
We explained earlier that even without the labeled data for which credit card purchases are fraudulent, it is still possible to flag suspicious purchases by simply monitoring the behavior of credit card users and identifying when behavior becomes ‘atypical.’ The flag can potentially trigger real-time notifications or interventions, for example calling or text messaging the cardholder. This simple action can not only improve outcomes by catching fraudulent purchases earlier, but also generates additional labeled data from the cardholder (confirmation of the purchase in question) for future utility.
Some research suggests that while vertical jump height is a measure that can be utilized to identify neuromuscular fatigue, monitoring changes to the underlying jump strategy may actually be more useful (3,4). Throughout our years of collecting force plate data on tens of thousands of individuals we have noticed that most healthy individuals have a relatively consistent movement strategy, or what we would call Movement Signature. So when an individual suddenly alters their movement strategy, this is definitely something worth investigating: perhaps fatigue is present, or pain or soreness at a specific joint… Underlying mental, emotional, or social stressors may significantly be impacting motivation or sleep…
This can alert clinicians when some sort of movement compensation is occurring that is atypical for that individual. This type of insight is well suited for the clustering techniques we’ve just discussed: we can automatically flag an individual after assessing if their cluster has changed, indicating a significant change from their ‘norm’ or baseline Movement Signature.
At Sparta Science, we have countless stories of practitioners uncovering meaningful information such as joint pain, academic-related stress, and even signs of eating disorders by consistently and objectively assessing movement strategies and monitoring for significant deviations from typical results or behavior. This objective information arms practitioners with the evidence to support their intuition and ultimately guide their interventions to achieve the best outcome.
Big Picture Takeaways
- Traditional statistical approaches were developed on small datasets, and while still useful, “big data” approaches should be leveraged on the growing number of large, complex datasets.
- Unsupervised learning provides a data-driven approach to uncovering hidden patterns or groupings from human movement and physiological data that are often assumed intuitively.
- The learnings that can be achieved with a “big data” approach can help to guide and support experts on decision-making and best practices for years to come.
References
- Shelly, Zachary, et al. “Using K-means clustering to create training groups for elite American football student-athletes based on game demands.” International Journal of Kinesiology and Sports Science 8.2 (2020): 47-63.
- Rauch, Jacob, et al. “Different Movement Strategies in the Countermovement Jump Amongst a Large Cohort of NBA Players.” International Journal of Environmental Research and Public Health 17.17 (2020): 6394.
- Legg, Jan, et al. “Variability of jump kinetics related to training load in elite female basketball.” Sports 5.4 (2017): 85.
- Gathercole, Rob, et al. “Alternative countermovement-jump analysis to quantify acute neuromuscular fatigue.” International journal of sports physiology and performance 10.1 (2015): 84-92.
Other posts you might be interested in:
View All Posts
Sparta Scan
14 min read
| July 13, 2021
Assessing Fatigue 101: What is Fatigue and How is it Measured?
Read More
Sports
4 min read
| July 8, 2019
The Death of Sport Specific Training – Discover Why You Need to Play the Man, Not the Game.
Read More
Human Data Platform
4 min read
| September 17, 2019