
June 30, 2023
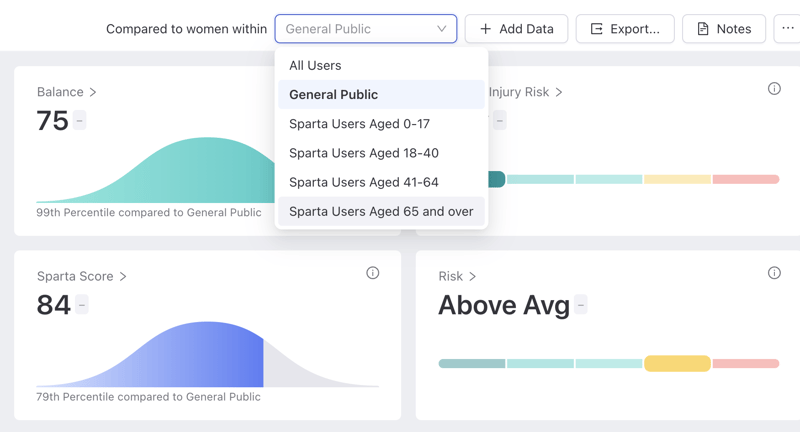
Organizations can benchmark, compare users, and inform intervention
Remember back in your school days when teachers graded on a curve? While some students dislike being compared to others, curve grading helps teachers logically categorize top, middle, and low performers to understand the distribution of scores and determine "good" scores from "poor" scores.
Along the same lines, Sparta Science’s Calculation Engine leverages population statistics to instantly sort users based on where they fall within their age range, organization, sex, or other relevant cohorts.
Take Kathryn, for example, a 60-year-old female who does a balance screening. While she may be in the 40th percentile for all females, age-relative comparisons impart more meaning. Knowing that she is in the 80th percentile for her age [among other relevant information] will help her healthcare provider determine that she may not be the best candidate for a fall-risk program.
Or Sebastian, a Navy recruit who scores in the 30th percentile compared to his peers in the Navy for strength measures. This information helps fitness and physical trainers adjust training protocols so his focus will be on increasing strength.
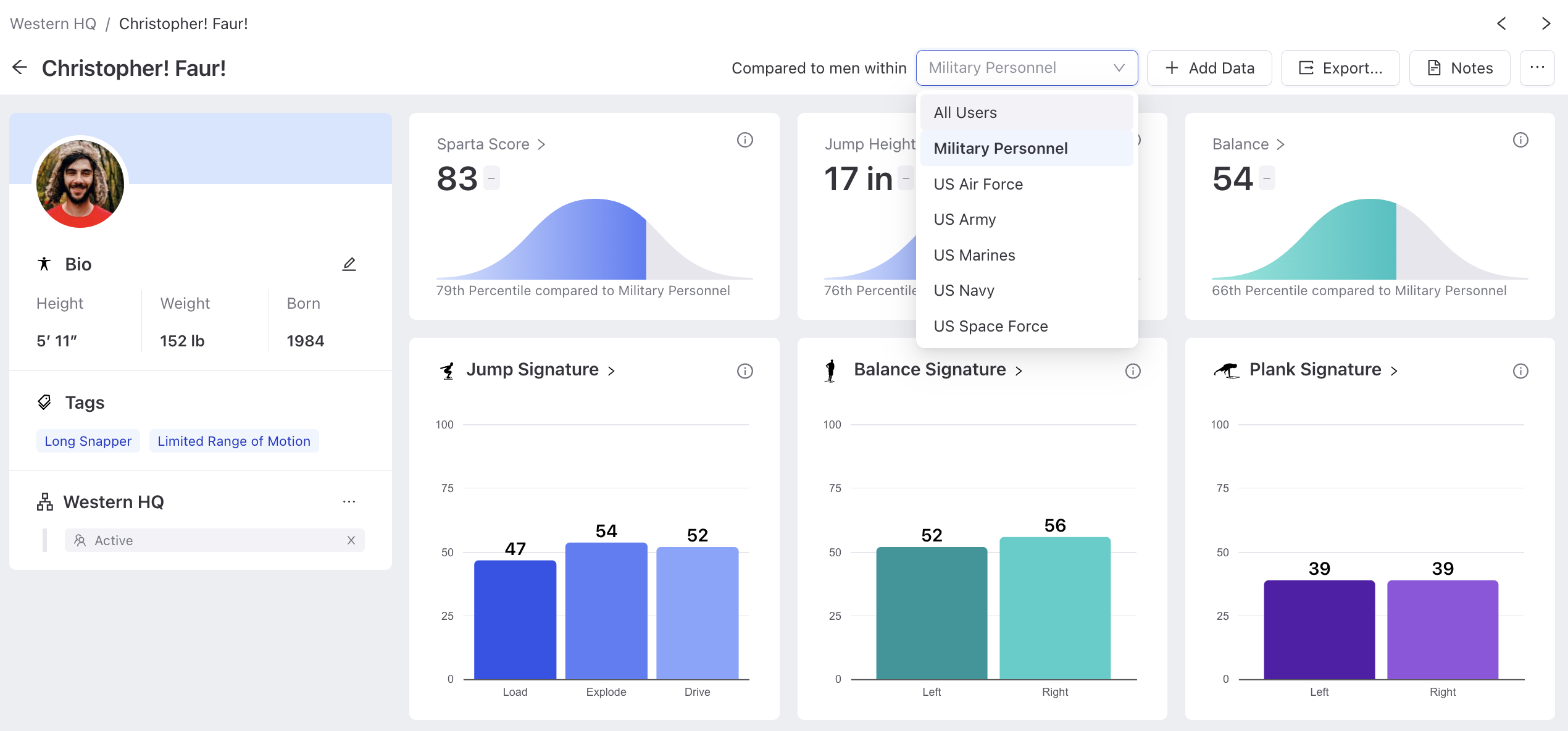
Backend data aggregation and normalization power actionable intelligence
At Sparta Science, we realize that most practitioners aren’t lacking in data but in how to best interpret and utilize data. This exemplifies some of the unique characteristics of human observation data that need consideration for turning data into actionable information. Within our data platform, we normalize data, removing the hassle of manual data crunching or normative table lookups for practitioners. From there, we instantaneously score users to save practitioners time and deliver synthesized insights. Data is displayed and interpreted through the context of that population or cohort. As a result, practitioners are equipped to discern actionable insights that drive informed decision-making and personalized care.
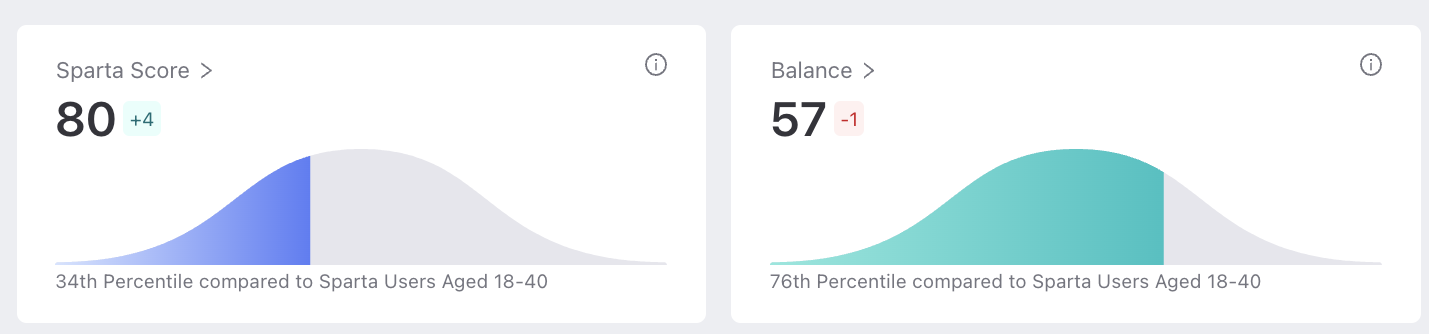
These insights help stakeholders see how scores compare to others in the same age range to understand how their results compare to a relevant cohort. They provide a point-in-time barometer of human data—on an individual and organization-wide level.
An extensive data lakehouse of relevant human data delivers meaningful insights
The technical infrastructure of our data platform provides flexible and scalable data storage, allowing our users to leverage a growing big-data asset to provide context to their data. This data is securely stored and managed, which allows new organizations to leverage anonymized population statistics from across our entire data lakehouse. The value of this data lies in its ability to help organizations with no baseline data understand how their populations compare to others with similar traits so that instead of starting from scratch, they get immediate insights and spend less time making sense of data. Given sufficient data, organizations can also leverage custom cohorts based specifically on their data and population to provide further specificity in context. While raw data and discrete calculated metrics are also easily accessible, our infrastructure allows organizations to leverage a growing pool of human data to improve interpretation.
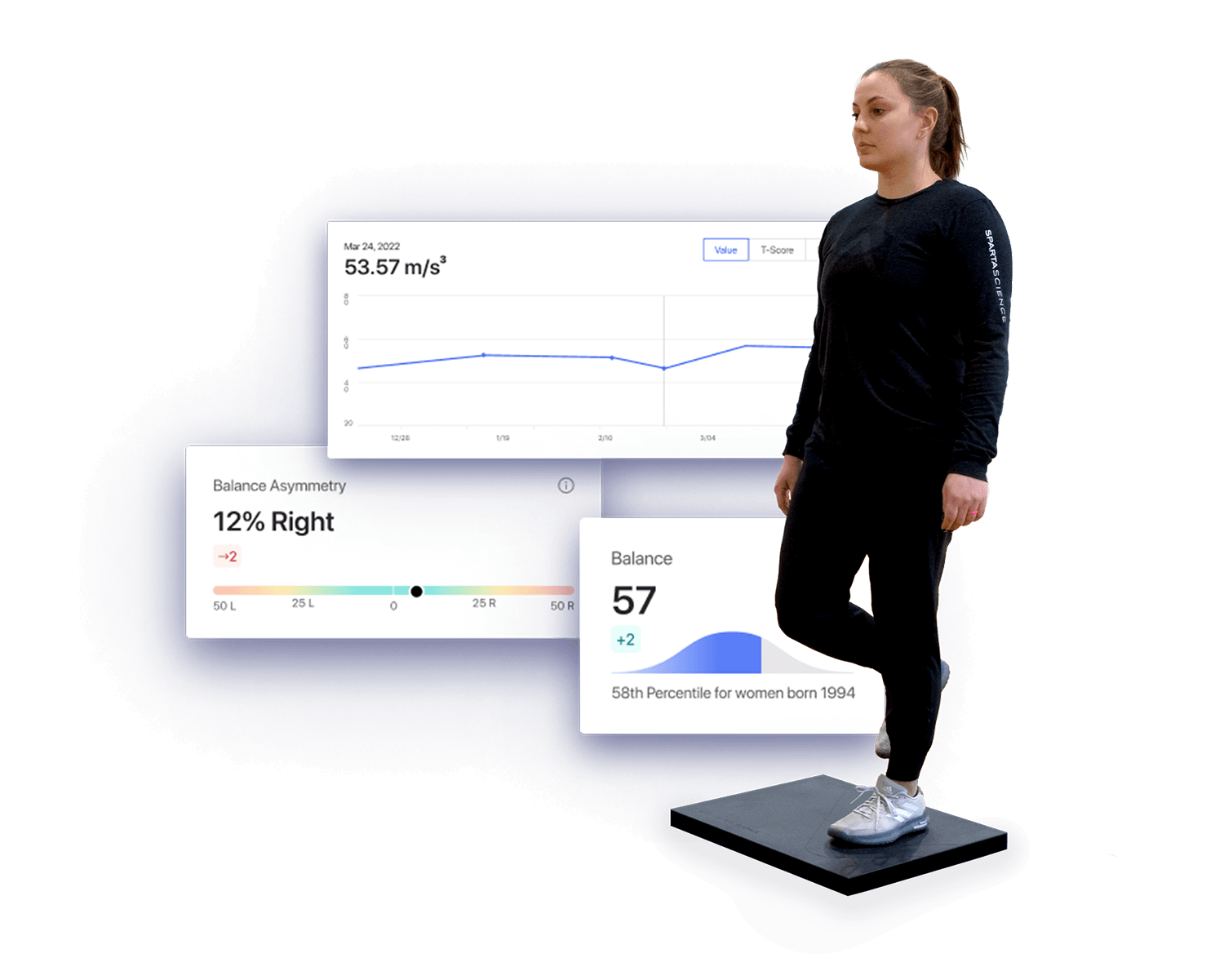
All data within our Human Data Platform is intelligently stored, with metadata that provides details about data fields, data relationships, data provenance, and more, enabling organizations to access their data more effectively and efficiently.
Enhanced relevancy and interpretability speed informed decision-making
Cohort comparisons allow different organizations and populations to use the same human observation data sources, metrics, and assessments while interpreting the information in a way that is tailored to their specific needs. By viewing data through different lenses, these groups can extract relevant and meaningful insights for their unique context. This ensures that the information is accurate but also applicable and interpretable, leading to more effective decision-making.
Sebastian, for example, may be in the 70th percentile for Men or the 50th percentile for Men between the ages of 18-40, but in the Navy, he’s in the 30th percentile. His strength-training efforts should allow him to advance to a higher percentile.

Workflow automation and instant results remove data-crunching headaches
With cohort comparisons, the need for manual calculations is minimized. Organizations can instantly see, for example, benchmarks on who in their population falls without having to calculate. The instant availability and built-in comparisons enhance efficiency and support timely actions.
Outliers and classification improve actionability and decision assistance
Cohort comparisons help identify key triage, resource allocation, and intervention thresholds. Organizations can prioritize resource allocation based on specific characteristics and needs by comparing individuals or groups to relevant cohorts. Furthermore, cohort comparisons enable the identification of outliers, both high-performing and high-risk individuals or groups. This information assists in making informed decisions and taking appropriate actions to improve performance or mitigate risks.
Heightens engagement and healthy competition
One of the intriguing aspects of cohort comparisons is the engagement it generates among end users. By comparing themselves to unrelated populations, individuals become more involved in the data and are motivated to improve or maintain their scores. The intuitive nature of cohort comparisons allows users to grasp their relative performance easily, fostering a sense of progress and achievement.

Informs resource allocation and benchmarking
Cohort comparisons play a vital role in resource allocation decisions. Organizations can implement actions and interventions based on objective data by considering relevant characteristics and comparing them in appropriate cohorts for previously unseen insights. Cohort comparisons facilitate individual benchmarking and allow for comparisons at the group and org-wide levels to unveil meaningful operational metrics.
Get tailored cohorts for your organization
Some organizations want to track and compare older populations for Fall Risk classification, while others may want to see how their NCAA basketball athletes or warehouse workers stack up. Whatever the use case, the Sparta Science Customer Success team works with each organization to understand its initiatives and devise the cohorts that make the most sense, considering the large pool of historical scans to compare against.